Machine Learning for Audio
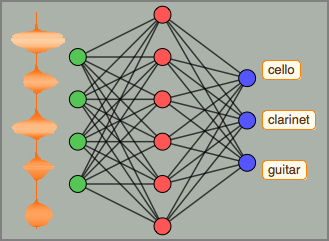
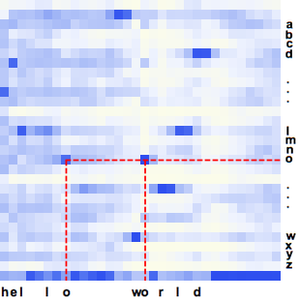
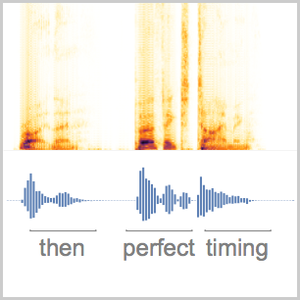
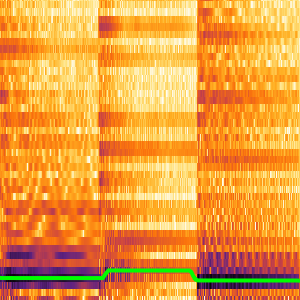
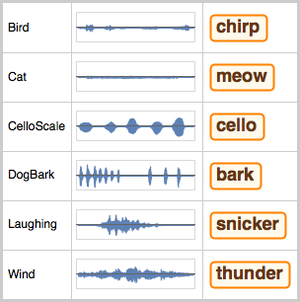
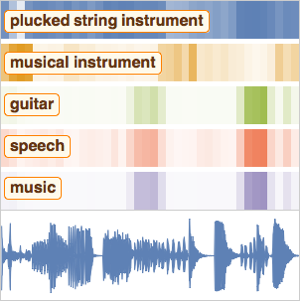
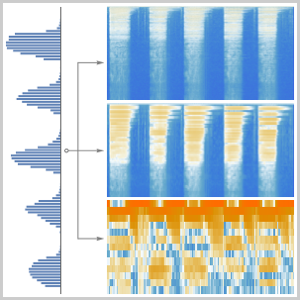
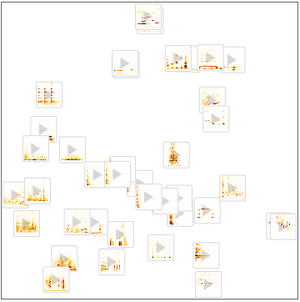
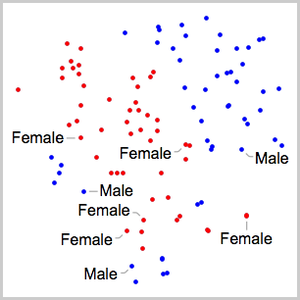
Version 12 audio processing and analysis provides high-level built-in functions for audio identification, speech recognition and more. An efficient and tight integration with the machine learning and neural net framework, as well as easy access to a growing number of state-of-the-art pre-trained models available through the Wolfram Neural Net Repository enables easy prototyping and development of algorithms. All of these capabilities form a rich, productive system to apply high-level and accurate machine learning solutions to a wide range of fields, such as speech and music.