Text and Language Processing
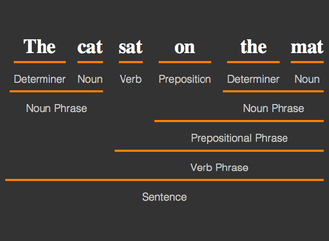
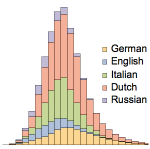
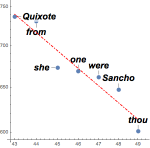
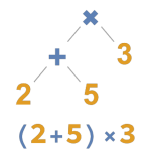
Mathematica Version 11 enhances the string, text, and natural language processing framework, providing new and more powerful functionality for symbolic manipulation and analysis of texts. New functions are available to identify and extract structured data from unstructured text, explore historical word frequency data, and parse natural language input.
Key Features
|
|