












Image & Audio
New in Image Processing
Version 12 continues to utilize modern machine learning and neural networks to add state-of-the-art, high-level, efficient computer vision functions for object detection and recognition, facial analysis, text recognition segmentation and many more. In addition, a large number of new functions and updates have been introduced to enable easier workflow of applications in research and development, computational photography, microscopy, astronomy, medicine and more.
New in Audio Processing

Version 12 introduces rich support for generating, capturing and searching for audio signals. It also continues to add powerful and highly optimized audio processing and analysis functions and introduces high-level analysis for audio identification, speech recognition and more. In addition, tight integration with the built-in machine learning and neural net capabilities enables easy and efficient prototyping of applications for understanding speech, music, communication signals and more.
Image Computation for Microscopy

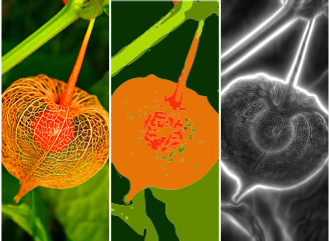
Version 12 adds new image processing functionality designed for specific tasks in microscopy, including biological sciences, material sciences, quality control and forensics. The capabilities range from brightness equalization to focus stacking and 3D reconstruction. In addition, with built-in machine learning and neural networks, the Wolfram Language is now the only high-level environment that provides advanced, state-of-the-art segmentation, feature extraction, object detection, classification and many more.
Machine Learning for Images

Version 12 image processing and computer vision use extensively updated machine learning and neural net capabilities and introduce several built-in, high-level functions for object recognition, face analysis, restyling and more. In addition, with a growing number of pre-trained networks available from the Wolfram Neural Net Repository, one can use available pre-trained networks immediately, or manipulate and reassemble them to train on new data. Powerful network surgery capabilities enable transfer learning, which allows for solving problems using much smaller datasets.
Machine Learning for Audio
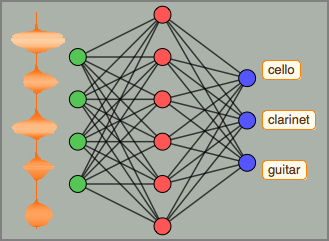
Version 12 audio processing and analysis provides high-level built-in functions for audio identification, speech recognition and more. An efficient and tight integration with the machine learning and neural net framework, as well as easy access to a growing number of state-of-the-art pre-trained models available through the Wolfram Neural Net Repository enables easy prototyping and development of algorithms. All of these capabilities form a rich, productive system to apply high-level and accurate machine learning solutions to a wide range of fields, such as speech and music.