












What's New in GAUSS 21
GAUSS 21 introduces a new and fast datamangement. The new dataframes and interactive data management make work more enjoyable and save hours of time.
Easy and Fast Data Management in GAUSS 21
New GAUSS dataframes make data easy to read and make code and results clearer
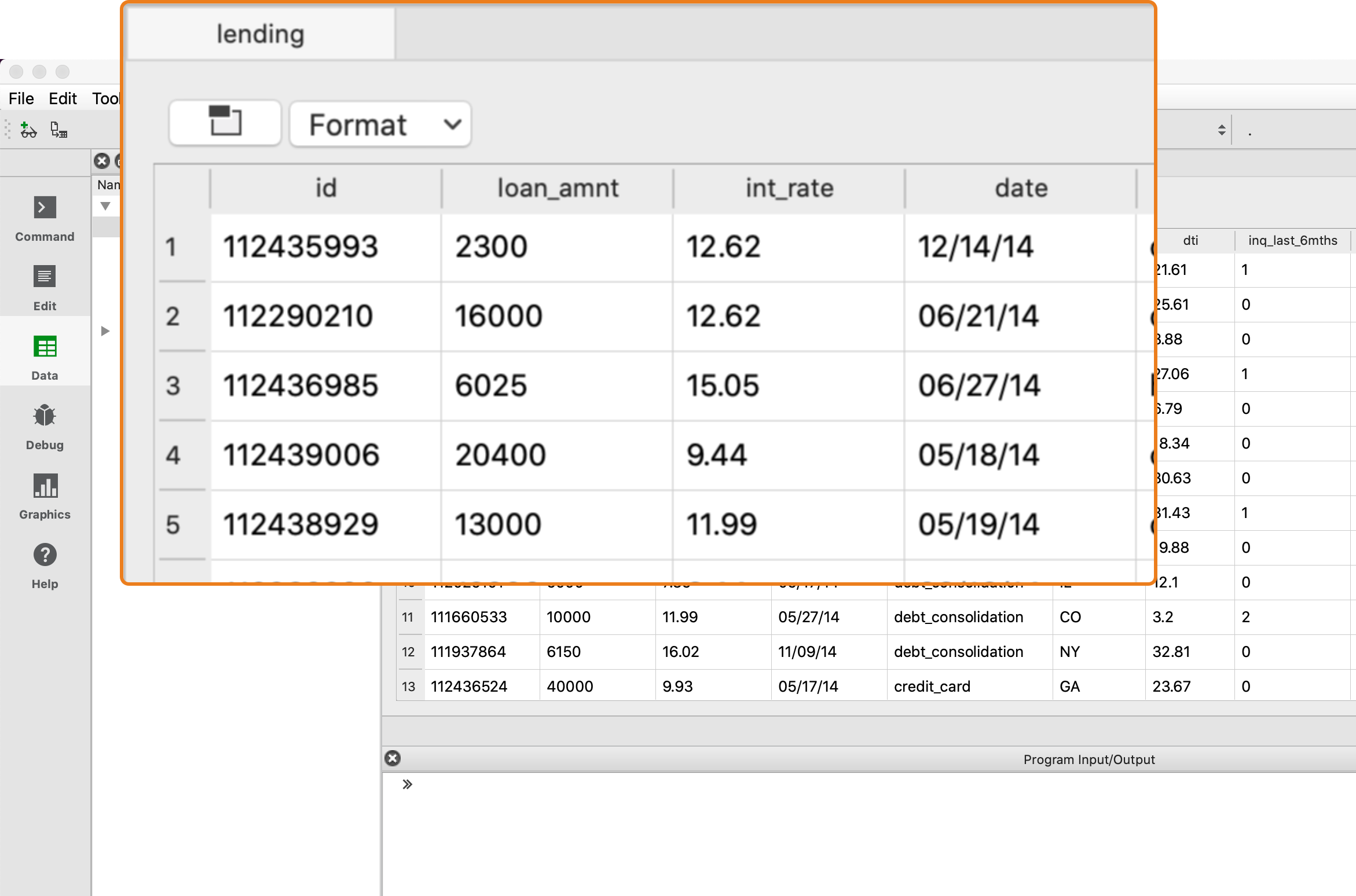
Customize your date display
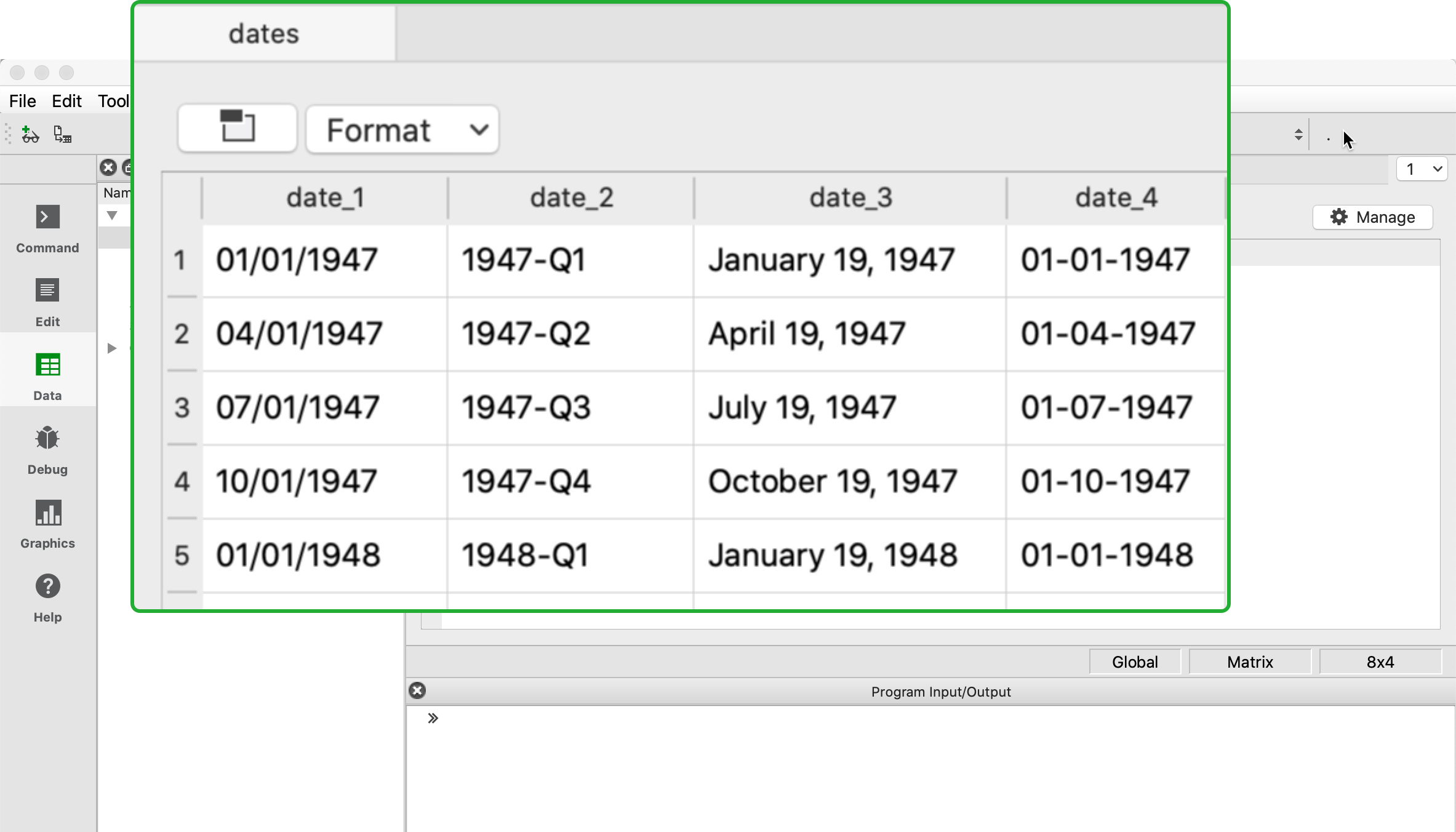
Reference your data by name

See your data your way with GAUSS dataframes
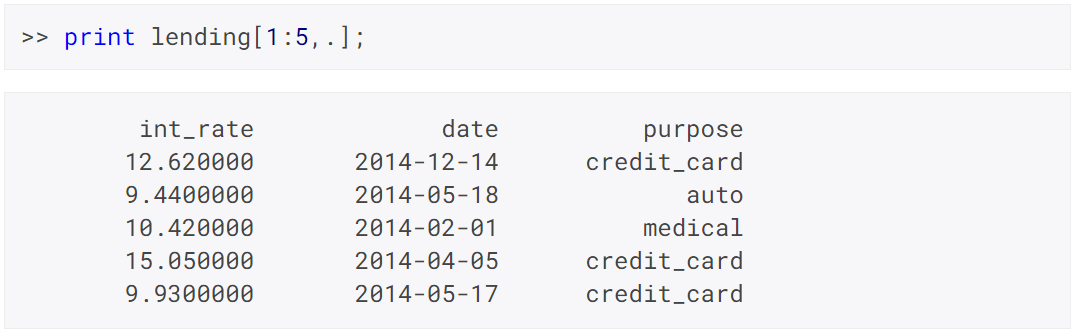
- Missing value support.
- Categorical, date, string, and numeric data.
- Reference by name or traditional matrix indexing.
- Programmatic and interactive support:
- Category base case, labels and order.
- Date display format.
- Simpler data cleaning.
- Clear data view and reporting.
- Compatible with matrices and older code and application modules.
Easy and fast interactive data management
Interactive data import
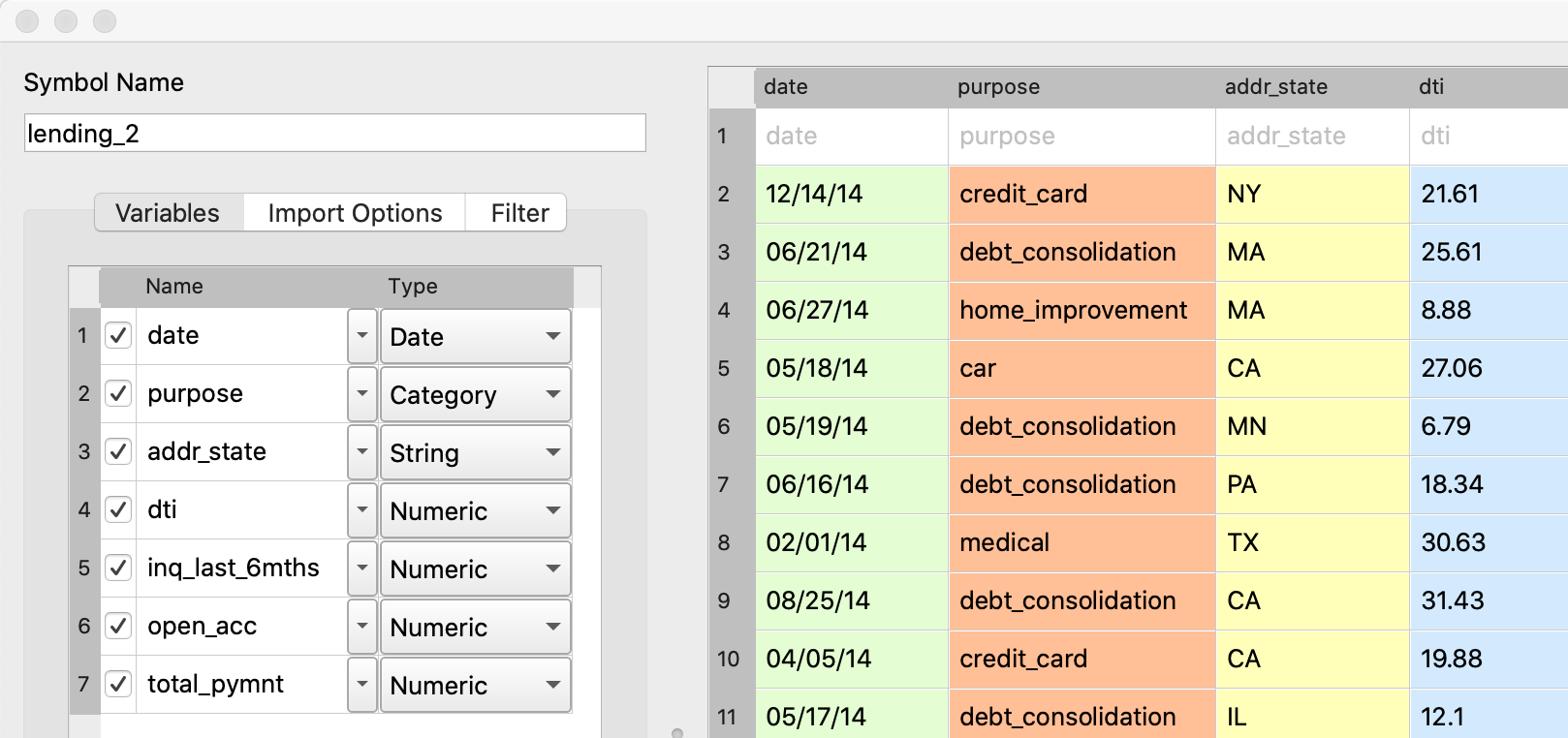
- One-click import and preview.
- CSV, Excel, SAS, Stata, SPSS files.
- Automatic code generation.
- Specify values to import as missing.
- Select and rename variables.
- Live preview.
- Manage categories.
View, rename, and reorder categorical variables
Intuitive interactive controls to:
- Set the base case.
- Rename labels.
- Set category order.
Import dates in any format
Non-standard date formats are no problem.
- Auto-detects 30 formats.
- Specify any custom format.
- Any characters.
- Any order.
Interactive data filter
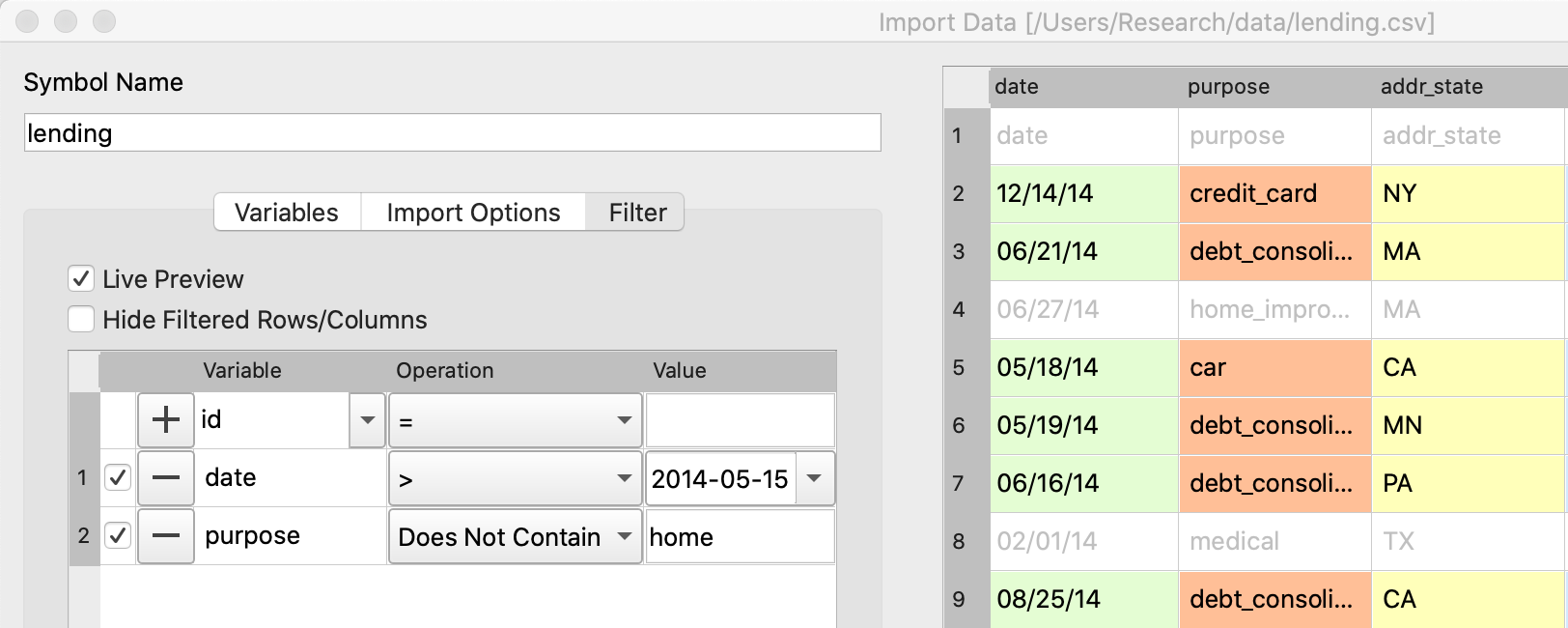
- Simple dropdown options.
- Create multiple filters.
- Automatic code generation.
- Available for data before and after loading.
- Handles missing data.
- Live preview.
- Intuitive date filtering.
Complete List of New Features
- GAUSS 21 now supports dataframes with date, categorical, string and numeric columns.
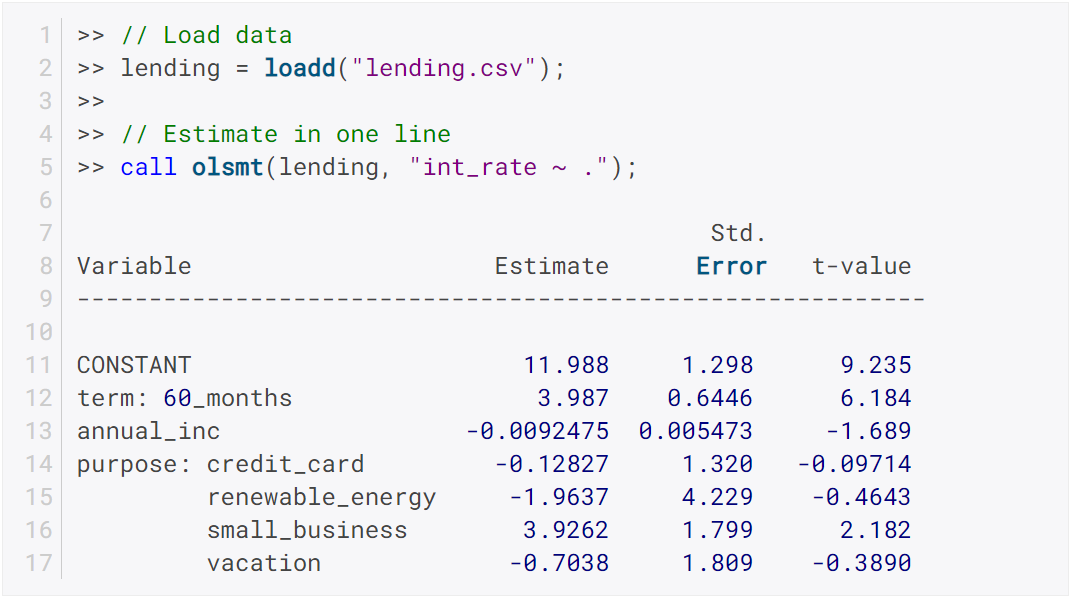
loadd()now returns a dataframe. This is a behavior change that can be reverted by the#definesinpolicy.dec.loadd()now accepts an optional input with support for additional data loading options, such as selecting a row range, specifying Excel sheets, CSV delimiters, the header row, values to interpret as missing values, and the quote character.loadFileControlCreate()fills aloadFileControlstructure with the defaults for the new data loading options.- Formula string keyword
catnow supports an optional input to set the base case. - Formula string keyword
datenow supports an optional input to specify the incoming date format. - Logical operators (
.<,.>,.<=,.>=,.==,.!=) support comparisons with date strings and categorical variable labels. glm()andolsmt()support dataframes and automatically turn categorical variables in to dummy variables.dstatmt()supports dataframes and counts missing values by default.saved()will write, string, categorical and date variables. The variable names argument is now optional.- New functions
setcolnames()andgetcolnames()set and return columns names of a matrix, or dataframe. - New functions
setcoltypes()andgetcoltypes()set and return the variable types of the columns of a matrix, or dataframe. - New function
setcolmetadata()sets column names and variable types for a matrix or dataframe. - New function
recodecatlabels()changes the labels displayed for a categorical variable in a dataframe. - New function
reordercatlabels()changes the order of the labels displayed for a categorical variable in a dataframe. - New function
setbasecat()sets the base category of a categorical variable. - New functions
setcollabels()andgetcollabels()set and return the integer key values and string labels of categorical variables in a dataframe. - New function
getcollabelvalues()returns the string labels for every observation of a categorical variable as a string array. - New function
setcoldateformats()sets the display format of a date variable,getcoldateformats()returns the display format. - New function
hasmetadata()returns a 1 if the input is a dataframe. - New function
asmatrix()turns a dataframe into the equivalent matrix. - New function
order()reorders columns of a dataframe by name. - New function
frequency()computes a frequency table for a categorical variable. - The Data Import Window now supports variable selection, interactive filtering and automatic code generation.
- The suffix for duplicate headers in the import dialog now start at _2 instead of _1.
- Symbol Editors support the same variable selection and filtering options added to the Data Import Window.
- Formatting in the Symbol Editor is now on a per column basis.
- Character vectors now show up to 8 characters in the Symbol Editor (the length is NOT limited for string arrays or dataframe string and category columns).
- CSV sniffing in the Data Import Window will now only occur for the first 200 rows instead of the entire file to improve performance.
- The Project Folders window now automatically shows contents of the Current Working Directory.
- The Project Folders window now shows new files without need to refresh.
- The default setting for the run button is now to run the active file. This can be changed in Preferences to be the same as previous versions.
- Find Usages for local variables now reports only instances of the local variable.
CTRL+F1will now find the declaration of local variables in a procedure.- New Preference option to specify the default directory for File > Open.
- Assignments to arrays of structures in
threadForloops is now allowed. - Bug fix: Memory leak in
lagtrim(). - Bug fix: Memory leak in specific situation with
EuropeanBSCall(). - Bug fix:
threadForwould not allow certain cases with multiple references to a slice variable to compile. - Control Var node on Data Page is now collapsed by default.
- New example files for dataframe 'get' and 'set' functions as well as
frequency()andplotFreq(). - GLM example files updated to use dataframes.