












Neu in GAUSS 18
Das Motto der neuen Version lautet: Noch effizienter von den Daten zum Ergebnis mit GAUSS 18. Die neuen Funktionen vereinfachen das Einlesen der Daten und deren Handhabung, erweitern die Analysewerkzeuge und die grafischen Möglichkeiten und bringen einen deutlichen Geschwindigkeitszuwachs.
Bessere Datenhandhabung
Verbesserte Handhabung der DatenLaden, Transformieren und Analysieren mit einem "Einzeiler":
- NEUE Formelnotation vereinfacht das Importieren und Transformieren der Daten
- Lesen von SAS- und STATA-Datensätzen
- Deutlich verbesserte Handhabung von sehr großen Datensätzen
NEUE Formelnotation vereinfacht das Importieren und Transformieren der Daten
//Load data, transform and estimate in one step
call ols("credit.xlsx", "ln(balance) ~ ln(income) + factor(sex)");
//Load data, reclassifying string column 'state' into numerical categories
X = loadd("census.csv", "income + household_size + reclassify(state)"); GAUSS 18 erweitert die bereits vorhandene einfache Formelsyntax und ermöglicht so drei Arbeitsschritte in einem: Einlesen, Transformieren und Analysieren der Daten:
- Drastisch verringerte Anzahl der nötigen Codezeilen
- Arbeitet mit CSV-, Excel-, GAUSS-Datensätzen, HDF5-, SAS- und STATA-Dateien
- Unterstützte automatische Transformationen umfassen:
- Funktionelle Transformationen, wie z. B. `ln`, `exp` oder andere GAUSS-Prozeduren
- Erstellen von Wechselwirkungen
- Erstellen von Dummy-Variablen
- Reklassifizierung von Stringvariablen
Einlesen von SAS- und STATA-Datensätzen
//Load SAS dataset, create interaction term and assign to GAUSS matrix 'X'
X = loadd("advertising.7bdat", "sales + radio * billboards + direct_mail");
//Load Stata dataset and compute descriptive statistics
call dstatmt("auto2.dta", "mpg + weight + gear_ratio");
Der Austausch von Daten zwischen GAUSS und anderer Software wurde jetzt noch einfacher gemacht. Nicht nur, dass GAUSS 18 den Import von SAS- und STATA-Datensätzen ermöglicht, es erlaubt sogar die direkte Verwendung von SAS-/STATA-Datensätzen als Basis für Funktionen wie OLS, GLM und der "General Method of Moments".
- Vollständige Kompatibilität mit SAS- und STATA-Daten
- Import von SAS- und STATA-Datensätzen als Datenmatrizen
- Verwendung von SAS- und STATA-Datensätzen als direkte Argumente in Funktionen
Verbesserter Umgang mit großen Datensätzen
//Load large data in consecutive 1 GB blocks
setBlockSize("1G");
//Load large data in consecutive blocks no larger than 10% of system memory
setBlockSize("10%"); Mit GAUSS 18 ist es einfach, auf große Datensätze zuzugreifen und diese zu analysieren. Die neuen Werkzeuge zum Datenhandling erlauben es dem Benutzer, die zu nutzenden Ressourcen genau zu beschreiben:
- Anteil des verfügbaren Speichers
- Einfache Speicherangaben
- Anzahl der Zeilen
Allgemeine Momentenmethode
Allgemeine Momentenmethode - die "General Method of Moments" (GMM)
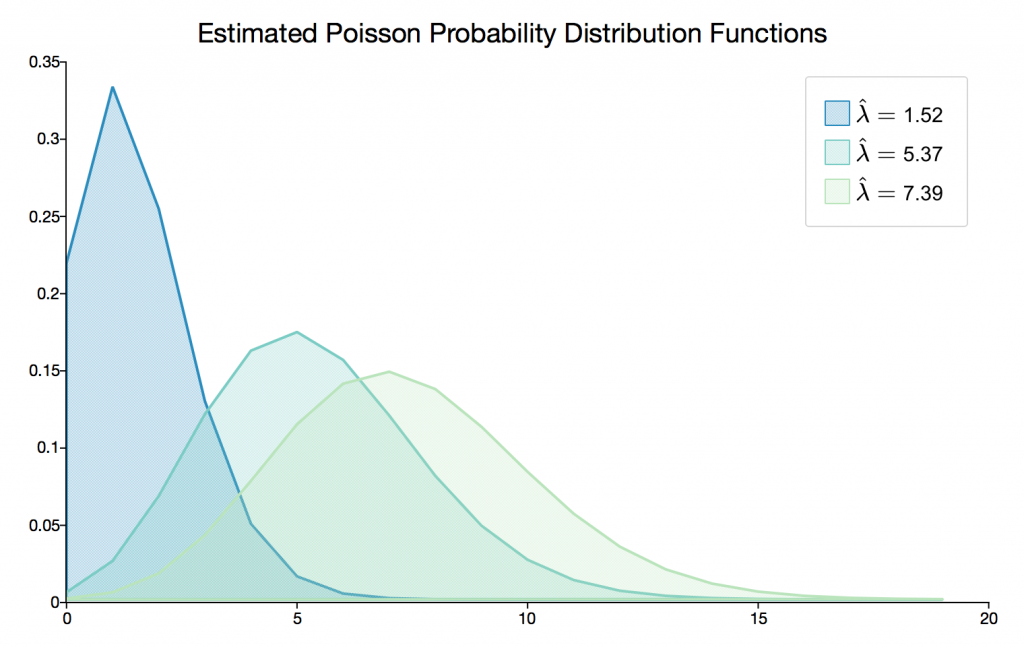
Die neu implementierte allgemeine Momentenmethode in GAUSS 18 schätzt die Parameter anhand von benutzerdefinierten Momentengleichungen oder durch analytische instrumentelle Variablen unter Verwendung der einschrittigen, zweischrittigen, iterativen oder der kontinuierlich aktualisierten GMM.
Neu implementierte GMM-Prozeduren:
- gmmFit bietet die volle Flexibilität inklusive benutzerspezifische Momentengleichungen.
- gmmFitIV bietet die analytische allgemeine Momentenmethode zur Abschätzung der instrumentellen Modellvariablen.
Die GAUSS-GMM-Prozeduren verfügen außerdem über neue robuste effiziente und anpassbare Werkzeuge:
- Ein-Schritt, Zwei-Schritt, Iterative, und stetig aktualisierende Schätzer der allgemeine Momentenmethode generalized method of moments estimation.
- Optionale instrumentelle Variablen
- Optionen für Standardfehler und Gewichtungsmatrix, inklusive tandard, heteroskedastic robust und HAC robust.
- Flexible initiale Gewichtungsmatrix
Graphische Funktionen
Graphische Funktionen
- Neue Farbpaletten und deren Optionen
- Programmierbare Größe der Zeichnungsfläche
- Weitere neue Funktionen
Vermitteln Sie Erkenntnisse durch moderne und professionelle Bilder.
Neue Farbpaletten und deren Optionen
Die neuen GAUSS-18-Werkzeuge für Farbpaletten vereinfachen die Verwendung in professionellen Layouts:
- Wählen Sie aus über 30 eingebauten Farbpaletten, neu entworfen für einen optimalen visuellen Eindruck.
- Vordefinierte Paletten für sequenzielle, quantitative und divergierende Daten
- Spezielle Paletten für farbenblinde Benutzer sind verfügbar.
- Erstellen Sie Ihre eigenen Paletten:
- Erstellen von gleichverteilten Farben im HSL-Hue-Farbraum
- Erstellen von gleichverteilten, zirkulierenden Farbtönen im HSLuv-Farbraum
- Mischen von Farben zur Erstellung von benutzerdefinierten Farbpaletten
Programmierbare Größe der Zeichnungsfläche
Einfache Erstellung und Reproduktion von Graphen, die Ihren Wünschen entsprechen. Die neue GAUSS-Prozedur `plotCanvasSize` definiert die Größe der Zeichenfläche basierend auf der Einheit Ihrer Wahl (Zentimeter, Millimeter, Inches oder auch Pixel).
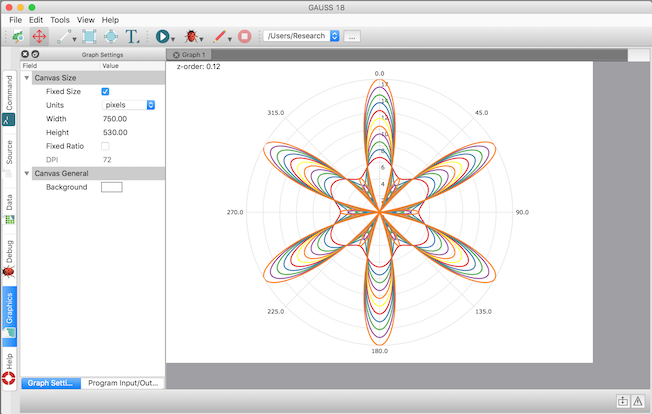
//Make this call before your plot to set the graph canvas
//to 750 px by 530 px as shown in the image above
plotCanvasSize("px", 750|530); Weitere neue Funktionen
string x_labels = { "Jan", "Feb", "Mar", "Apr", "May", "Jun" };
plotXY(x_labels, y); - Einfache Anwendung von Zeichenketten als Beschriftungen für Achsen in jedem 2D-Graphen, wie z. B. Punktplot, XY-Plot und anderen
- Hinzufügen jeglicher 2D-Graphen (wie Punktplots) zu Konturgraphen
- Die neue FunktionplotSetTicLabelFont definiert die Schriftart, Schriftgröße und Schriftfarbe der X- und Y-Hilfsstrichsbeschriftungen.
New Productivity Functions
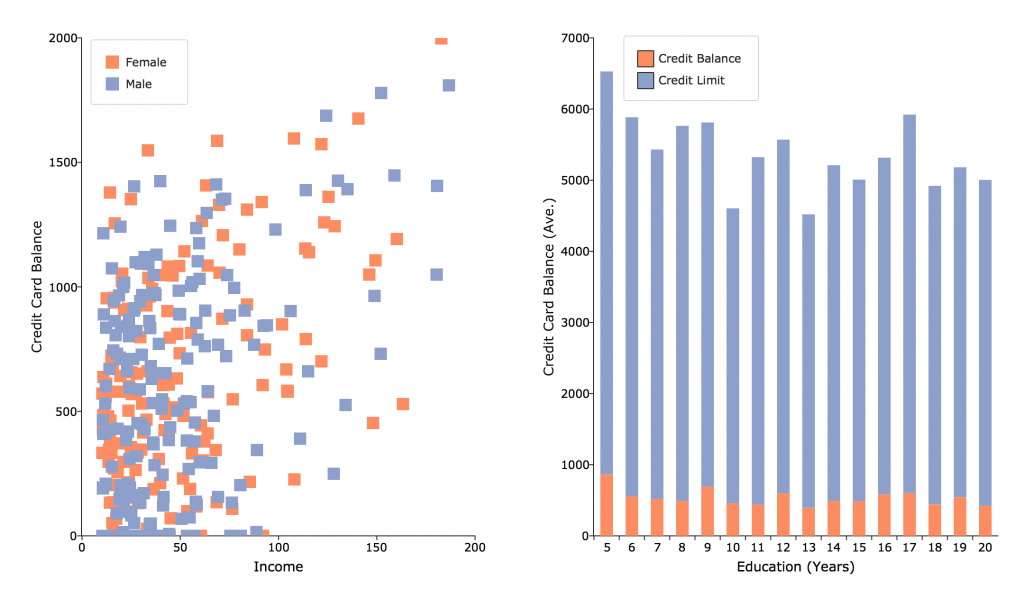
Steigerung der Effizienz
Erhöhen Sie Ihre Produktivität durch die neuen GAUSS-18-Funktionen zur effizienten Navigation und Organisation Ihrer Daten. Entdecken Sie Zusammenhänge schneller durch neue Werkzeuge zur Suche, Reorganisation sowie Zusammenfassung von Daten und vielem mehr!
-
Die neuen Funktionen innerJoin und outerJoin ermöglichen die flexible Kombination von Matrizen.
ab = innerJoin(A, 1, B, 1); - Erstellen von diagonalen Blockmatrizen durch die Verwendung von blockDiag.
.
//'blockDiag' can create block matrices from 1, 2 or more input matrices d = blockDiag(A, B); - Entdecken, ob eine Matrix, ein Array oder ein Zeichenketten-Array ein oder mehrere Elemente aus einer Liste enthält.
//Find whether 'X' contains any elements in 'list' any = contains(X, list); - Feststellen, welche Elemente einer Matrix einem oder mehreren bestimmten Elementen entsprechen, durch die Verwendung von ismember.
//Find which elements in 'X' match any elements from 'list' match = ismember(X, list); - Einfache Navigation durch Auf-/Zuklappen von multidimensionalen Feldern mit Hilfe der
squeeze-Funktion.
//Remove any singleton dimensions from 'A' A = squeeze(A); - Rückgabe des vollständigen Pfades zur Programmdatei ungeachtet des Ablageortes durch die Variable __FILE_DIR.
//With your program and data in the same directory, __FILE_DIR //allows you to easily find your data regardless of your //working directory--greatly simplifies code sharing data_file = __FILE_DIR $+ "mydata.csv"; //Prefer to keep your data in a different relative path? //No problem, __FILE_DIR works easily in this situation as well data_file = __FILE_DIR $+ "../data/mydata.csv"; - Entfernen von bestimmten Spalten einer Matrix durch delcols.
//Remove the 3rd and 5th columns from 'A' A = delcols(A, 3|5); - Ersetzen aller zutreffenden Teil-Zeichenketten in einer großen Zeichenkette oder einem Feld von Zeichenketten durch strreplace.
//Regularize addresses: Avenue to Ave address = strreplace(address, "Avenue", "Ave"); - Die Kompatibilität für Felder wurde auf die Funktionen erf, erfc, erfcinv, erfc, pdfn und den Potenzoperator erweitert.
Geschwindigkeitssteigerungen
Geschwindigkeitssteigerungen
- Die verkettete Zusammenführung von Zeichenketten arbeitet jetzt 2 - 4 x schneller
- X'Y für den Vektor zu Vektor Fall arbeitet 15 % - 600 % schneller für Vektoren mit Längen über 50 Elementen
- Deutliche Steigerung der Geschwindigkeit für das Indizieren kleinerer Matrizen
- Die beschreibende Statistik mit dstatmt und OLS mit ols arbeiten jetzt 15 - 30 % schneller für mittlere und große Matrizen.
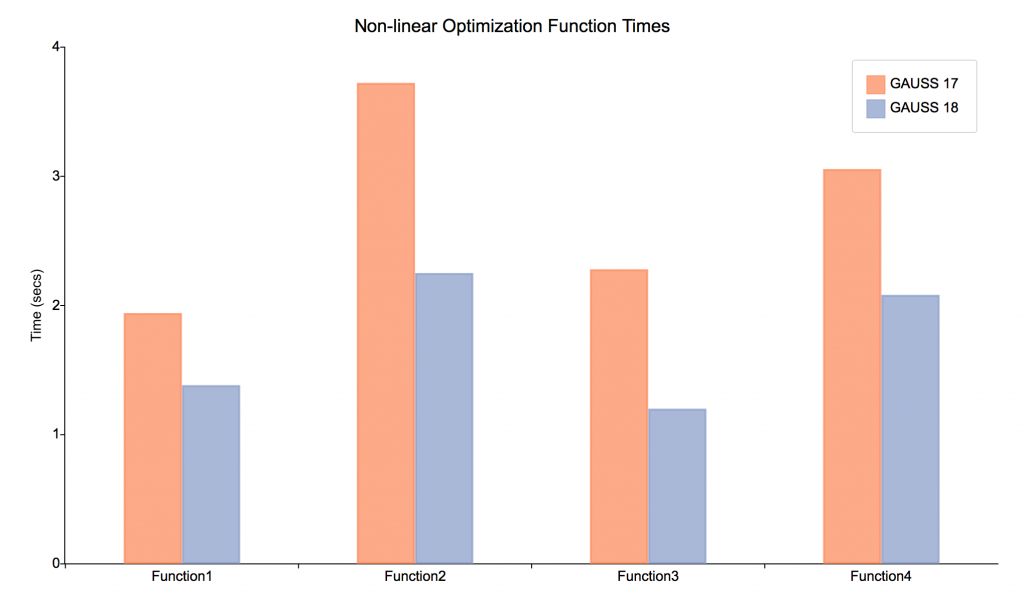
Beispiel für nichtlineare Funktionen
Zur Verdeutlichung der möglichen Geschwindigkeitssteigerungen bei der Indizierung und dem Verketten wurden zwei nichtlineare Funktionen beispielhaft definiert. Der nachstehende Code wurde zur Erstellung der weiter unten gezeigten Vergleichsgrafik verwendet:
proc fct_a(x);
local f1,f2,f3;
f1 = 3*x[1]^3 + 2*x[2]^2 + 5*x[3] - 10;
f2 = -x[1]^3 - 3*x[2]^2 + x[3] + 5;
f3 = 3*x[1]^3 + 2*x[2]^2 -4*x[3];
retp(f1|f2|f3);
endp;
proc fct_b(x);
local ff1, ff2, ff3, ff4, ff5, ff6, ff7, P;
P = 20;
ff1 = 0.5*x[1] + x[2] + 0.5*x[3] - x[6]/x[7];
ff2 = x[3] + x[4] + 2*x[5] - 2/x[7];
ff3 = x[1] + x[2] + x[5] - 1/x[7];
ff4 = -28837*x[1] - 139009*x[2] - 78213*x[3]
+ 18927*x[4] + 8427*x[5] + 13492/x[7]
- 10690*x[6]/x[7];
ff5 = x[1] + x[2] + x[3] + x[4] + x[5] - 1;
ff6 = (P^2)*x[1]*x[4]^3 - 1.7837e5*x[3]*x[5];
ff7 = x[1]*x[3] - 2.6058*x[2]*x[4];
retp(ff1|ff2|ff3|ff4|ff5|ff6|ff7);
endp;
Mathematische Funtionen
Mathematische Funtionen
- besselk berechnet die modifizierte Bessel-Funktion der 2. Art; nützlich für die negative, inverse Gaussian-Verteilung.
- rndRayleigh berechnet Rayleigh-verteilte Zufallszahlen.
- gmmFit und gmmFitIV schätzen mittels der allgemeinen Momentenmethode.
- cdfTruncNorm, pdfTruncNorm, cdfLogNorm und pdfLogNorm
- Optionale mu- und sigma-Parameter für cdfn und pdfn
- Array-Unterstützung für erf, erfc, erfcinv, erfc, pdfn und power op.