












Neu in GAUSS 23
Die neue Version GAUSS 23 legt den Fokus auf Zeitersparnis beim Finden, Importieren und Modellieren von Daten.
Daten jederzeit zur Hand
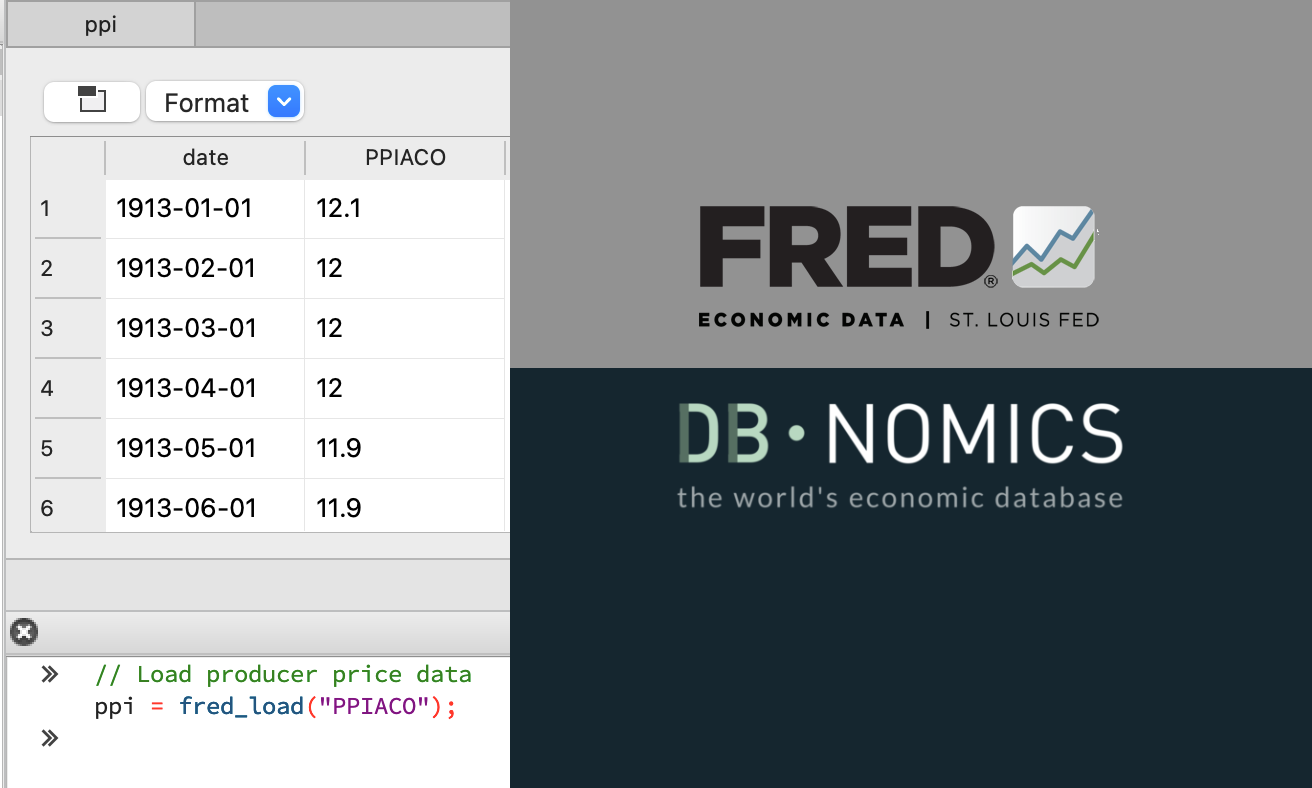
- Zugriff auf Millionen von globalen Wirtschafts- und Finanzdatenreihen mit der Integration von FRED und DBnomics
- FRED-Datenreihen bereits während des Imports aggregieren, filtern, sortieren und transformieren
- FRED-Serien aus GAUSS heraus durchsuchen
Daten von überall aus dem Internet laden

Vereinfachtes Laden von Daten
Automatische Typerkennung
Die intelligente Datentyperkennung in GAUSS 23 ermittelt den Variablentyp bei Datumsvariablen, Strings und kategorialen Variablen, so dass er nicht mehr manuell angegeben werden muss. Die automatische Erkennung umfasst u. a. fast 40 gängige Datumsformate.


Automatische Erkennung von Kopfzeilen und Trennzeichen
GAUSS 23 behandelt beim Laden von Daten automatisch
- vorhandene/fehlende Kopfzeile
- Trennzeichen (Tabulator, Komma, Semikolon oder Leerzeichen)
- Anzahl der Zeilen und Spalten
- Variablentyp
Alter Quellcode
load X[127,4] = mydata.txt;
Neuer Quellcode
X = loadd("mydata.txt");
Einfache Dataframe-Speicherung
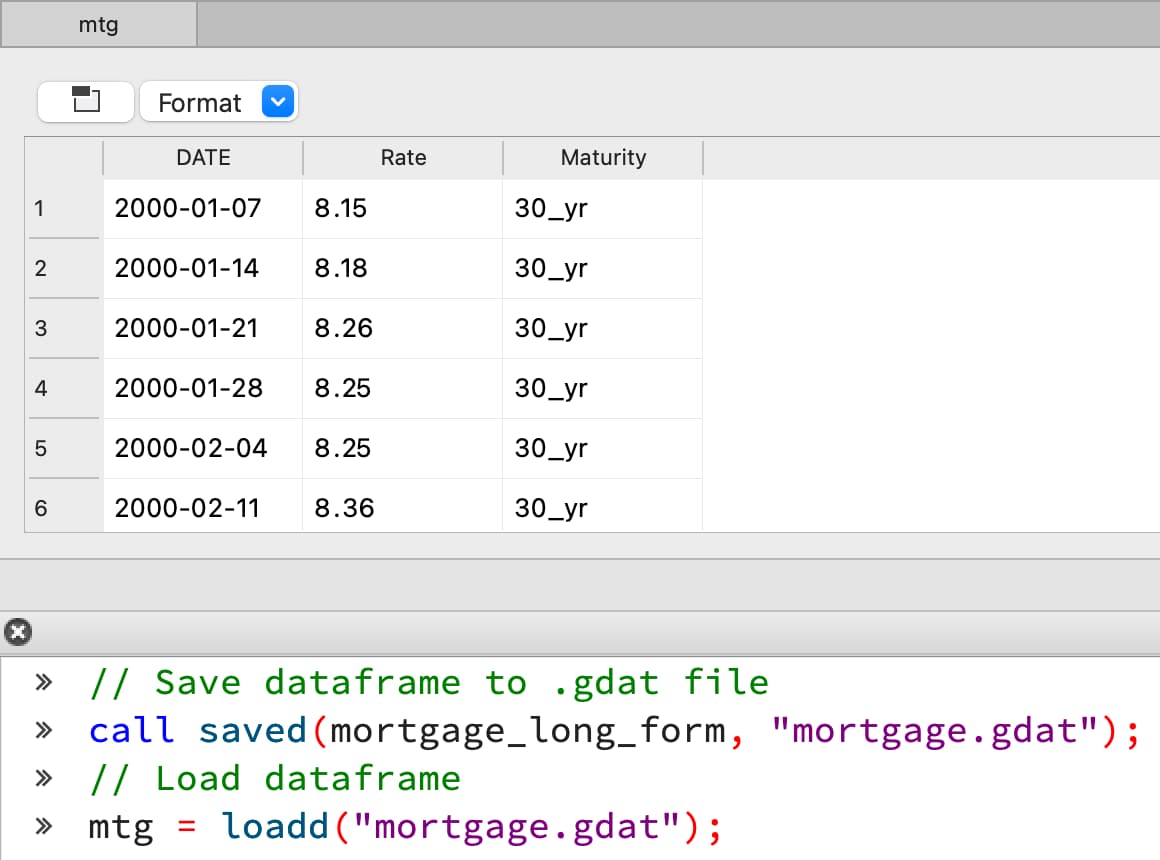
Die Befehle loadd und saved in Kombination mit der .gdat-Dateierweiterung in GAUSS 23 laden und speichern Dataframes unkompliziert ab, ohne dass eine neue Syntax erlernt werden muss.
Erweiterte Quantilregressionen
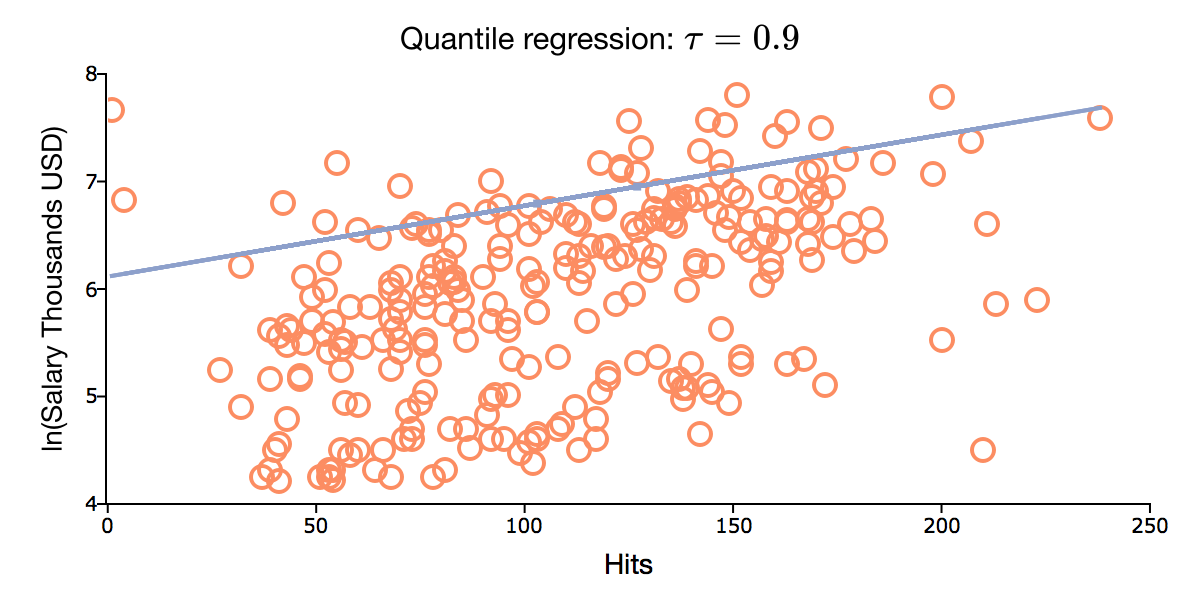
- neue Kernel-geschätzte Varianz-Kovarianz-Matrix
- bis zu 4-fache Verbesserung der Geschwindigkeit
- erweiterte Modelldiagnose einschließlich Pseudo-R-Quadrat, t-Statistiken und p-Werte für Koeffizienten sowie Freiheitsgrade


Kernel-Dichte-Schätzungen
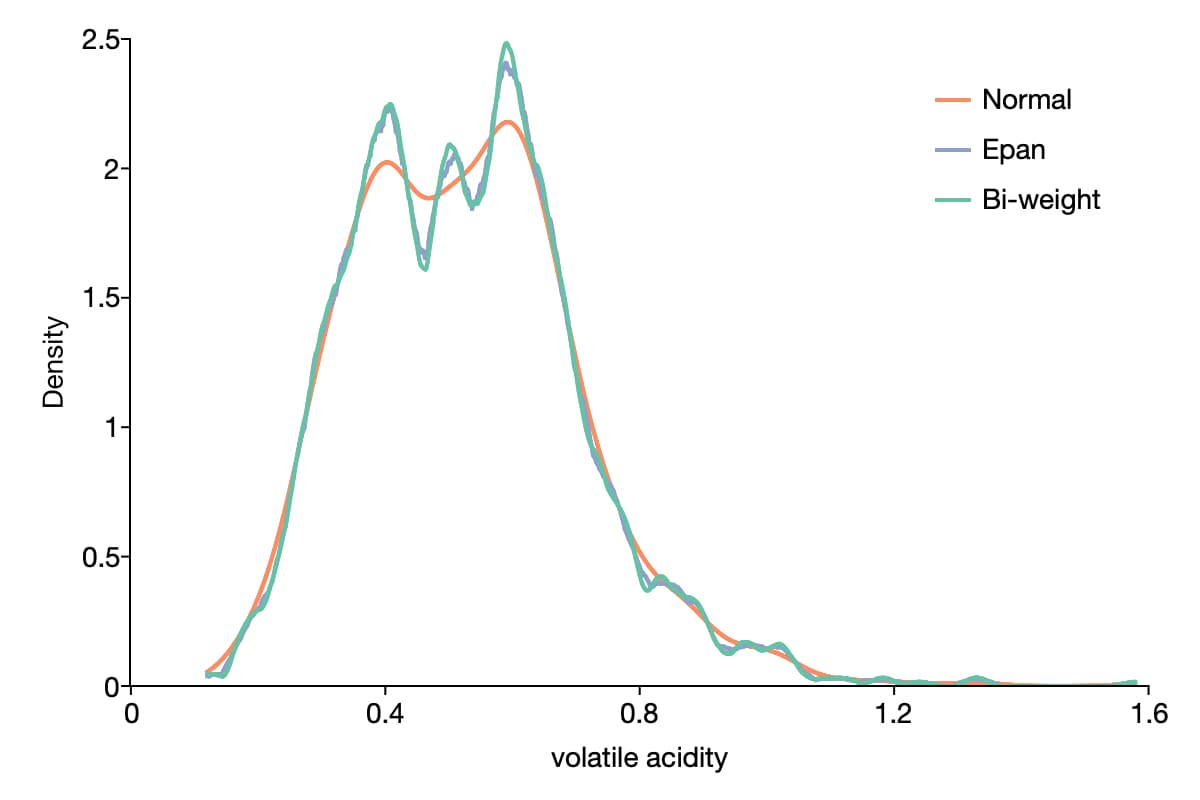
- Schätzung unbekannter Wahrscheinlichkeitsfunktionen mit 13 verfügbaren Kerneln
- automatische oder benutzerdefinierte Bandbreite
- Kernel-Dichte-Diagramme mit benutzerfreundlichen Optionen zur Anpassung
Verbesserte Kovarianzberechnungen
- neues Verfahren zur Berechnung von robusten Standardfehlern nach Newey-West HAC
- Alle robusten Kovarianzverfahren enthalten jetzt die Option, die Korrekturen für kleine Stichproben zu deaktivieren.
- erweiterte Kompatibilität von Dataframes und Formelstrings
Neue Funktionen für Datenbereinigung und -exploration
- Funktionen
skewnessundkurtosiszum Untersuchen der Symmetrie von Stichproben und deren Enden - Funktion
JarqueBerazum Test auf Normalität
between
Die Funktion between gibt einen binären Vektor zurück, der angibt, welche Beobachtungen in einen bestimmten Bereich fallen. Der Befehl kann mit selif verwendet werden, um Zeilen auszuwählen. Datumsangaben und ordinale kategoriale Spalten werden unterstützt.


where
Die Funktion where bietet eine bequeme und intuitive Möglichkeit, Daten zu kombinieren oder zu ändern. Sie gibt je nach Condition (Bedingung) entweder Elemente aus a oder b zurück.


Verbesserungen bei Geschwindigkeit und Effizienz
- bis zu 10-fache Beschleunigung und 50-prozentige Verringerung des Speicherbedarfs bei der Erzeugung von Verzögerungen mit
shiftcundlagn - bis zu 2-fache Beschleunigung (oder mehr bei großen Daten) und 50 % weniger Speicherbedarf für
miss,missrv - bis zu 2-fache Beschleunigung (oder mehr bei großen Daten) und 50 % weniger Speicherbedarf für elementweise mathematische (
+,-,.*,./), relationale (.>,.<,.>=,.<=,.==,.!=) und logische (.and,.not,.or,.xor) Operatoren - bis zu 100-fache Beschleunigung für einige Fälle mit
indsav - bis zu 40 % schneller bei
reclassify - bis zu 3-fache Beschleunigung beim Laden von Excel®-Dateien mit
loaddund dem Datenimportfenster