
")















Neu in GAUSS 25
GAUSS 25 verbessert die Arbeitsabläufe mit neuen intuitiven Werkzeugen für die Datenexploration, erweiterte Diagnosen und nahtlose Modellvergleiche.
Umfassende Werkzeuge für Paneldaten
GAUSS 25 transformiert die Art und Weise, wie Daten geladen, analysiert und erforscht werden durch neue intuitive Werkzeuge.
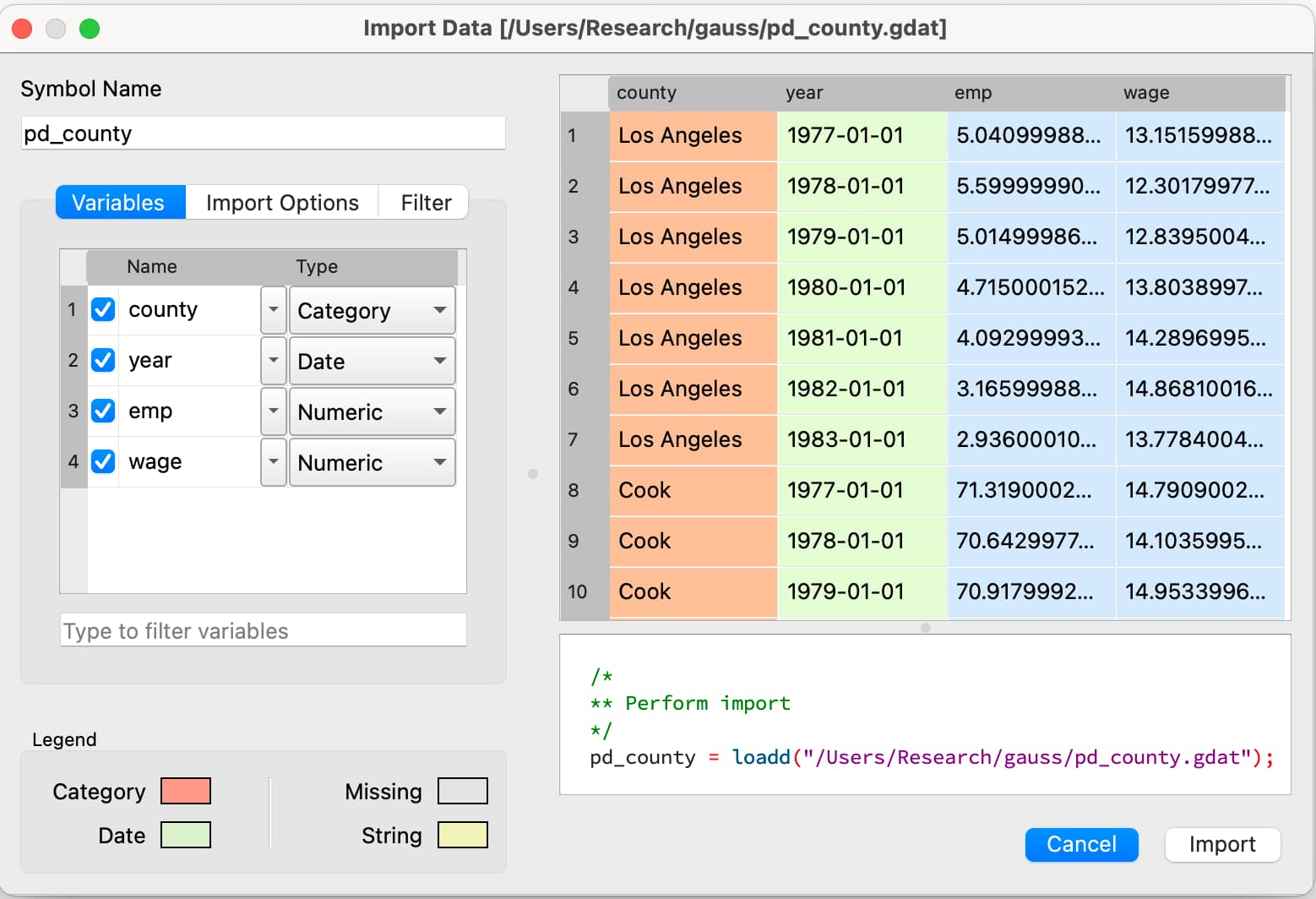
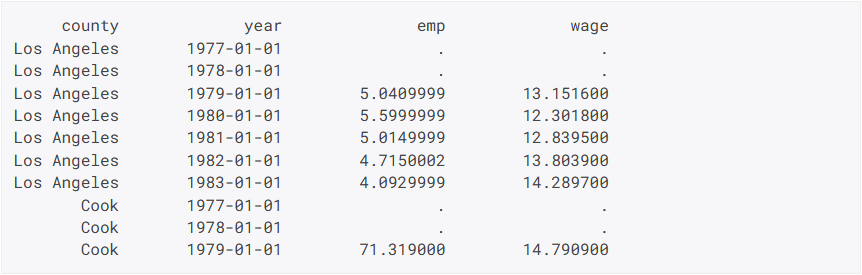
Merkmale von Paneldaten untersuchen
- Mit der neuen Funktion
pdSummarykönnen allgemeine, gruppeninterne und gruppenübergreifende zusammenfassende Statistiken untersucht werden.

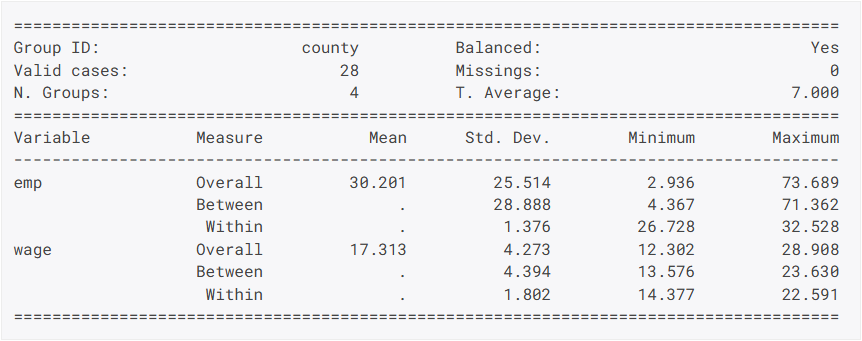
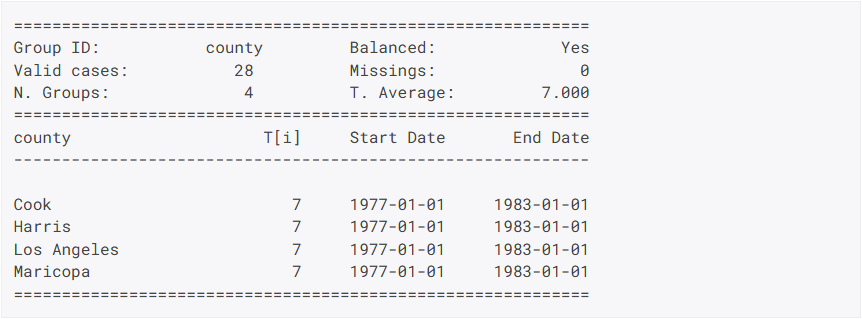
- Zeitverteilungen von Paneldaten können mit den Funktionen
pdSizeundpdTimeSpansbetrachtet werden.

Paneldaten für die Modellierung vorbereiten
- Automatisierte und intelligente Erkennung von Gruppen- und Zeitvariablen für nahtlose Arbeitsabläufe
- Sofortige Sortierung von Paneldaten nach erkannten Gruppen- und Zeitvariablen mit
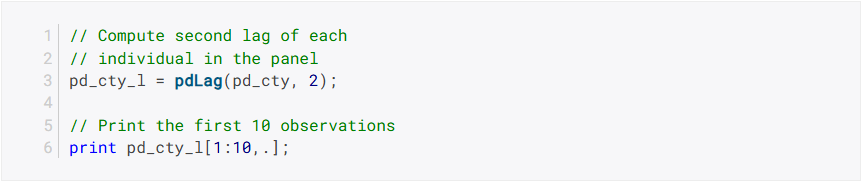
pdSort - Neue Befehle
pdLagundpdDifffür die Berechnung von Verzögerungen und Differenzen von Paneldaten
- Neue Befehle
pdAllBalancedundpdAllConsecutivefür die Überprüfung, ob Daten balanciert und fortlaufend sind
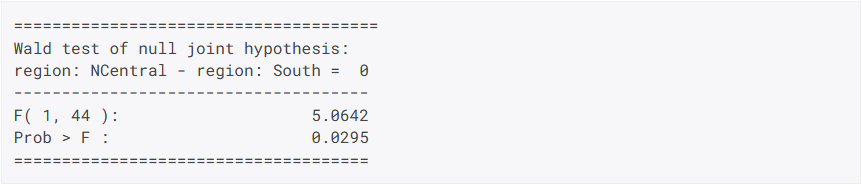
Neue Hypothesentests
Die neue waldTest-Prozedur bietet ein leistungsstarkes und intuitives Werkzeug zum Testen linearer Hypothesen nach der Schätzung.
- Hypothesentests nach der Schätzung nach OLS, GLM, GMM und Quantilregression durchführen
- Hypothesen mühelos mit Hilfe von Variablennamen spezifizieren
- Umfassende Unterstützung für die lineare Kombination von Variablen in Hypothesen

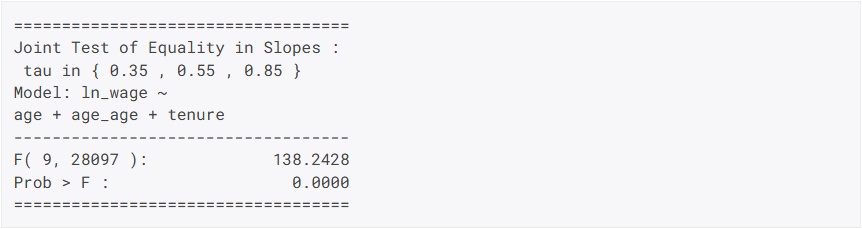
Mit dem neuen qfitSlopeTest-Befehl kann die Gleichwertigkeit der Steigungen zwischen Quantilen nach der Quantilsregression geprüft werden.

Verbesserte Ergebnisausdrucke
GAUSS 25 bietet nun erweiterte Modelldiagnosen und konsistente Ausdrucke für alle Schätzverfahren.

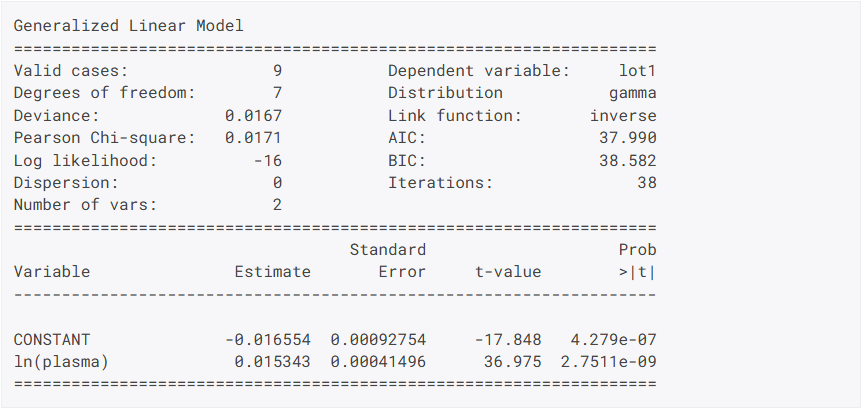
Die Verbesserungen machen es noch einfacher, Modelle zu vergleichen, Ergebnisse zu untersuchen und tiefere Einblicke zu gewinnen.
Verbesserte Leistung und höhere Geschwindigkeit
- Erweiterte Zwei-Wege-Tabellierung unter Verwendung des
tabulate-Befehls, um Zeilen- oder Spaltenprozentsätze zu finden - Die Funktion
gmmFitIVverwendet jetzt Metadaten aus Datenrahmen, um Variablennamen zu identifizieren und zu berichten, und unterstützt das Schlüsselwort "by". - Die optionale Angabe von sortierten Daten führt zu Geschwindigkeitsverbesserungen bei der Verwendung des Befehls
counts. - Die
plotFreq-Prozedur unterstützt jetzt das Schlüsselwort "by" für die Zählung von Häufigkeiten über Gruppen hinweg.

savederkennt und speichert nun automatisch kategorische und String-Variablen unter Verwendung ihrer Bezeichnungen für Excel-Dateien.